uberonpeek -- a look at UBERON ontology, etc., with ontoProc2
Vincent J. Carey, stvjc at channing.harvard.edu
July 13, 2026
Source:vignettes/uberonpeek.Rmd
uberonpeek.RmdIntroduction
The ontoProc2 package is designed to give convenient access to the ontologies that are transformed to “semantic SQL” in the INCAtools project.
We’ll start by retrieving the current UBERON ontology and examining some tables and “statements”.
library(ontoProc2)
library(DBI)
library(dplyr)
ubss <- semsql_connect(ontology = "uberon")
report(ubss)##
## ============================================================
## SemsqlConn Object
## ============================================================
##
## Connection Details:
## ----------------------------------------
## Database path: /home/runner/.cache/R/BiocFileCache/1cc458b15eb1_uberon.db
## Ontology prefix: UBERON
## Status: ✓ Connected
##
## Database Statistics:
## ----------------------------------------
## Labeled terms: 28,764
## Direct edges: 80,942
## Entailed edges: 6,421,630
## Definitions: 23,007
##
## Terms by Prefix (top 5):
## ----------------------------------------
## UBERON: 16,067
## GO: 7,433
## CL: 1,477
## _: 1,260
## CHEBI: 917
##
## Key Tables Available:
## ----------------------------------------
## ✓ rdfs_label_statement
## ✓ has_text_definition_statement
## ✓ edge
## ✓ entailed_edge
## ✓ rdfs_subclass_of_statement
## ✓ owl_some_values_from
## ✓ has_oio_synonym_statement
##
## ============================================================
## Use methods like search_labels(), get_ancestors(), etc.
## Run ?SemsqlConn for documentation.
## ============================================================
ubcon <- ubss@con
head(dbListTables(ubcon))## [1] "all_problems" "annotation_property_node"
## [3] "anonymous_class_expression" "anonymous_expression"
## [5] "anonymous_individual_expression" "anonymous_property_expression"
tbl(ubcon, "statements")## # A query: ?? x 8
## # Database: sqlite 3.53.3 [/home/runner/.cache/R/BiocFileCache/1cc458b15eb1_uberon.db]
## stanza subject predicate object value datatype language graph
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 obo:uberon.owl obo:uberon.owl foaf:home… NA http… xsd:any… NA NA
## 2 obo:uberon.owl obo:uberon.owl rdfs:comm… NA Aure… NA NA NA
## 3 obo:uberon.owl obo:uberon.owl oio:treat… NA ZFS … NA NA NA
## 4 obo:uberon.owl obo:uberon.owl oio:treat… NA ZFA … NA NA NA
## 5 obo:uberon.owl obo:uberon.owl oio:treat… NA XAO … NA NA NA
## 6 obo:uberon.owl obo:uberon.owl oio:treat… NA WBls… NA NA NA
## 7 obo:uberon.owl obo:uberon.owl oio:treat… NA WBbt… NA NA NA
## 8 obo:uberon.owl obo:uberon.owl oio:treat… NA TGMA… NA NA NA
## 9 obo:uberon.owl obo:uberon.owl oio:treat… NA TAO … NA NA NA
## 10 obo:uberon.owl obo:uberon.owl oio:treat… NA TADS… NA NA NA
## # ℹ more rowsParent-child relations
CRAN’s ontologyIndex package provides a familiar representation that simplifies visualization.
uboi <- semsql_to_oi(ubcon)## Warning in ontologyIndex::ontology_index(name = nn, parents = pl): Some parent
## terms not found: BFO:0000001, COB:0000502, CARO:0000000 (4 more)
uboi## Ontology with 25854 terms
##
## Properties:
## id: character
## name: list
## parents: list
## children: list
## ancestors: list
## obsolete: logical
## Roots:
## CHEBI:24432 - biological role
## CHEBI:51086 - chemical role
## CHEBI:33232 - application
## CHEBI:23367 - molecular entity
## BFO:0000003 - occurrent
## CHEBI:24433 - group
## CHEBI:33250 - atom
## BFO:0000002 - continuant
## UBERON:0035943 - life cycle temporal boundary
## CARO:0000007 - immaterial anatomical entity
## ... 3 more
uboi$name[10364:10370]## $`NCBITaxon:9935`
## [1] "Ovis"
##
## $`NCBITaxon:9963`
## [1] "Caprinae"
##
## $`NCBITaxon:9971`
## [1] "Pholidota"
##
## $`NCBITaxon:9972`
## [1] "Manidae"
##
## $`NCBITaxon:9975`
## [1] "Lagomorpha"
##
## $`NCBITaxon:9989`
## [1] "Rodentia"
##
## $`PATO:0000001`
## [1] "quality"A sense of the variety of ontological cross-references present can be given by tabling the tag prefixes.
## prefs
## BFO BSPO CARO CHEBI CL COB GO IAO
## 14 12 5 915 1474 5 7428 5
## NBO NCBITaxon PATO PR RO UBERON
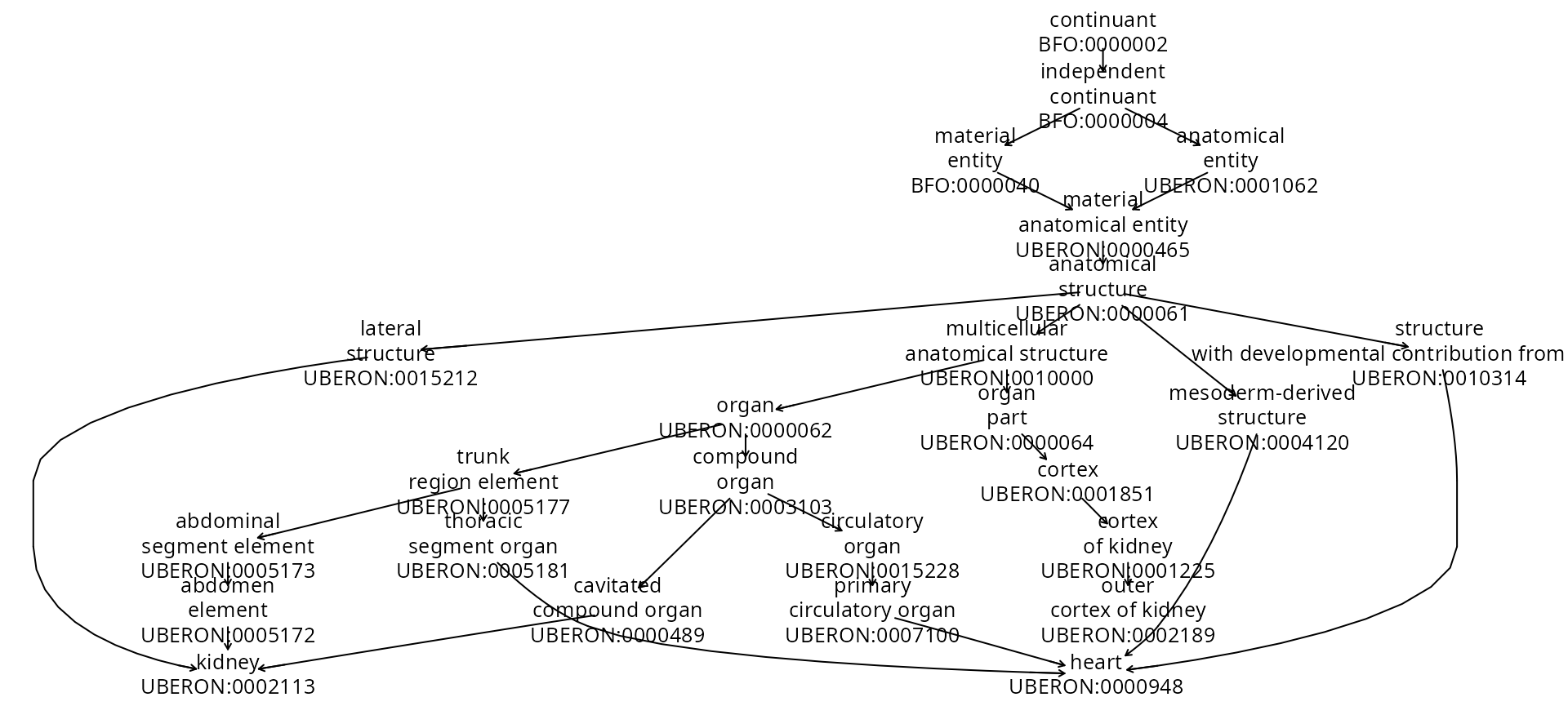
## 37 474 159 353 1 14972By using the ancestors component we can obtain a view of is-a relations (presumably developed from rdfs:subClassOf predicates). We’ve chosen as terminal tags the tags for heart, kidney, and cortex of kidney.
onto_plot2(
uboi,
unlist(uboi$ancestors[c(
"UBERON:0002189",
"UBERON:0002113", "UBERON:0000948"
)])
)
Bridging to MONDO for disease terminology
With our knowledge of the tag for “heart”, we can enumerate formal terms for diseases affecting this organ.
mon = semsql_connect(ontology="mondo")## Connected to SemanticSQL database: /home/runner/.cache/R/BiocFileCache/1d3e5ee9e37a_mondo.db## Primary ontology prefix: MONDO
tbl(mon@con, "entailed_edge") |>
filter(object == "UBERON:0000948") |>
filter(subject %like% "MONDO%") |>
inner_join( tbl(mon@con, "rdfs_label_statement"), by="subject") |>
as.data.frame() |> select(subject, value) |> distinct() |> DT::datatable()Bridging to CL for cell type enumeration
cl = semsql_connect(ontology="cl")## Connected to SemanticSQL database: /home/runner/.cache/R/BiocFileCache/19c7a780bc1_cl.db## Primary ontology prefix: CL
tbl(ubcon, "entailed_edge") |>
filter(object == "UBERON:0000948") |>
filter(subject %like% "CL:%") |>
inner_join( tbl(cl@con, "rdfs_label_statement"), by="subject", copy="temp-table") |>
as.data.frame() |> select(subject, value) |> distinct() |> DT::datatable()Exercise: create a map from cardiac diseases to associated cardiac cell types.
Session information
## R version 4.6.1 (2026-06-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] dplyr_1.2.1 DBI_1.3.0 ontoProc2_0.99.28 BiocStyle_2.40.0
##
## loaded via a namespace (and not attached):
## [1] xfun_0.60 bslib_0.11.0 httr2_1.2.3
## [4] htmlwidgets_1.6.4 ontologyPlot_1.7 vctrs_0.7.3
## [7] tools_4.6.1 crosstalk_1.2.2 generics_0.1.4
## [10] stats4_4.6.1 curl_7.1.0 tibble_3.3.1
## [13] RSQLite_3.53.3 blob_1.3.0 pkgconfig_2.0.3
## [16] R.oo_1.27.1 dbplyr_2.6.0 S7_0.2.2
## [19] desc_1.4.3 graph_1.90.0 lifecycle_1.0.5
## [22] compiler_4.6.1 textshaping_1.0.5 htmltools_0.5.9
## [25] sass_0.4.10 yaml_2.3.12 pillar_1.11.1
## [28] pkgdown_2.2.1 jquerylib_0.1.4 R.utils_2.13.0
## [31] DT_0.34.0 cachem_1.1.0 tidyselect_1.2.1
## [34] digest_0.6.39 purrr_1.2.2 bookdown_0.47
## [37] paintmap_1.0 fastmap_1.2.0 grid_4.6.1
## [40] cli_3.6.6 magrittr_2.0.5 utf8_1.2.6
## [43] withr_3.0.3 filelock_1.0.3 rappdirs_0.3.4
## [46] bit64_4.8.2 rmarkdown_2.31 bit_4.6.0
## [49] otel_0.2.0 ragg_1.5.2 R.methodsS3_1.8.2
## [52] memoise_2.0.1 evaluate_1.0.5 knitr_1.51
## [55] BiocFileCache_3.2.0 rlang_1.3.0 ontologyIndex_2.12
## [58] glue_1.8.1 Rgraphviz_2.56.0 BiocManager_1.30.27
## [61] xml2_1.6.0 BiocGenerics_0.58.1 jsonlite_2.0.0
## [64] R6_2.6.1 systemfonts_1.3.2 fs_2.1.0